文本文件和字符集
- java是完全基于Unicode的,但是 os 一般有它们自己的字符编码,比如在 美国是 ISO-8859-1(8位代码,有时候也称为 ANSI 代码), 在台湾是 Big5;
- 当把数据保存到一个文本文件中时,应该照顾到本地的字符编码,这样,用户就可以用它们的其他程序打开这个文本文件。
- 字符编码是在 FileWriter 的构造器中指定的: out = newFileWriter(filename, “ISO-8859-1”);
- problem:遗憾的是, 目前,locale 和字符编码间没有任何联系。 比如, 你的 用户选择的是台湾的locale_zh_TW, 但是在 java中并没有提供任何方法来告诉你用 Big5 字符编码是最恰当的;
源文件的字符编码
- 作为 coder, 要牢记你需要与java 编译器进行交互: 这种交互需要通过本地系统的工具来完成;
- 使用中文版的记事本来写你的java 源代码文件, 但这样写出来的源代码不能随处使用;因为它们使用的是本地的字符编码;只有编译后的class 文件才能随处使用, 因为它们会自动地使用 “modified UTF-8” 编码来处理标识符和字符串。
这意味着即使在程序编译和运行时,依然有3种字符编码参与其中:
- 源文件: 本地编码;
- 类文件: modified UTF-8;
- 虚拟机: UTF-16;
为了使你的源文件到处都可用, 必须使用普通 的 ASCII 编码: 也就是说, 你需要将所有 非ASCII 字符转换成等价的 Unicode 编码;
- jdk 有一个工具 native2ascii :可以用它来将本地字符编码转换为 普通 的 ASCII , 这个工具直接将输入中的每一个非 ASCII 字符替换为 跟尾儿 \u 加上四位 16进制数字的Unicode值;(干货——native2ascii 工具的作用)
- 如何使用 native2ascii 工具:
native2ascii Myfile.java Myfile.temp - 用 -reverse 进行逆向转换:
native2ascii -reverse myfile.temp myfily.java - 用 -encoding 选项指定另一种编码:编码的名字必须是 编码表所列出来的名字之一, 如: native2ascii -encoding Big5 myfile.java myfile.temp
看个栗子
- native2ascii HelloWorld.java HelloWorld.temp
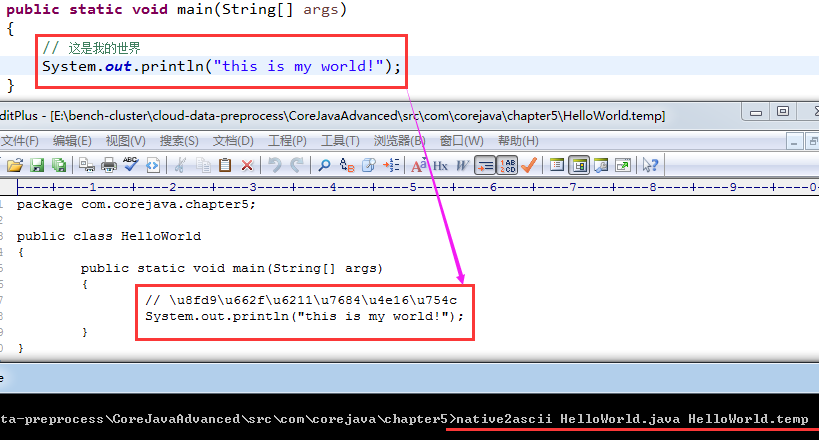
- native2ascii -encoding Big5 HelloWorld.java HelloWorldTW.temp
- native2ascii -reverse HelloWorld.temp Reverse.java
- native2ascii HelloWorld.java HelloWorld.temp


转自https://blog.csdn.net/PacosonSWJTU/article/details/50636153


